你有没有想过,在浩瀚的互联网世界里,视频可是占据了半壁江山呢!无论是搞笑段子、教程教学,还是热门剧集,视频都能让你轻松获取信息,享受娱乐。但是,你知道如何轻松地爬取这些视频吗?今天,就让我带你一起探索Python爬视频的奥秘吧!
一、Python爬视频的必要性
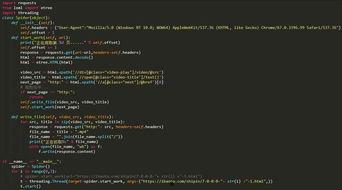
在这个信息爆炸的时代,我们每天都会接触到大量的视频内容。但是,这些视频往往分散在不同的平台上,想要一一观看,实在是一件费时费力的事情。而Python爬视频,就能帮你轻松解决这个问题。
首先,Python爬视频可以让你快速获取所需视频资源。无论是学习教程,还是热门剧集,通过爬取,你都可以轻松下载到本地,随时随地观看。
其次,Python爬视频可以帮助你进行数据分析和研究。通过对大量视频数据的爬取和分析,你可以了解用户喜好、视频流行趋势等,为你的工作提供有力支持。
再者,Python爬视频可以让你实现个性化推荐。通过分析用户观看视频的习惯,你可以为用户推荐他们可能感兴趣的视频,提高用户体验。
二、Python爬视频的准备工作
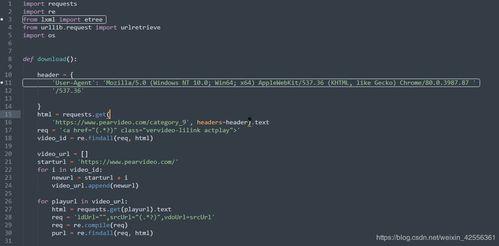
在开始爬视频之前,你需要做好以下准备工作:
1. 安装Python环境:首先,确保你的电脑上已经安装了Python环境。如果没有,可以去Python官网下载并安装。
2. 安装第三方库:Python爬视频需要用到一些第三方库,如requests、BeautifulSoup、pyquery等。你可以在命令行中使用pip命令进行安装。
3. 了解视频网站结构:在爬取视频之前,你需要了解目标网站的结构。这包括视频的URL格式、视频封面、视频时长等信息。
三、Python爬视频的实战技巧
下面,我将为你介绍几种常见的Python爬视频方法:
1. 使用requests库获取视频页面内容:
```python
import requests
url = 'https://www.example.com/video_page'
response = requests.get(url)
html_content = response.text
2. 使用BeautifulSoup解析视频页面内容:
```python
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
video_tag = soup.find('video')
video_url = video_tag['src']
3. 下载视频:
```python
import os
video_name = 'example.mp4'
video_path = os.path.join('download', video_name)
with open(video_path, 'wb') as f:
f.write(requests.get(video_url).content)
4. 使用pyquery库解析视频页面内容:
```python
from pyquery import PyQuery as pq
doc = pq(url)
video_url = doc('.video').attr('src')
5. 使用Selenium模拟浏览器行为:
```python
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(url)
video_url = driver.find_element_by_tag_name('video')['src']
四、注意事项
1. 遵守网站规则:在爬取视频时,一定要遵守目标网站的规则,避免对网站造成过大压力。
2. 合理设置爬取速度:为了不影响目标网站,建议合理设置爬取速度,避免短时间内大量请求。
3. 处理异常情况:在爬取过程中,可能会遇到各种异常情况,如网络错误、页面结构变化等。这时,你需要学会处理这些异常情况,保证爬取过程顺利进行。
4. 尊重版权:在爬取视频时,一定要尊重版权,不要用于非法用途。
Python爬视频是一项非常有用的技能。通过学习Python爬视频,你可以轻松获取所需视频资源,提高工作效率。快来试试吧!